Claude Code has quietly become the most productive line item on a lot of engineering teams. It is also one of the easiest bills to lose track of. Token usage is invisible until you hit a limit or open an invoice, it scales with how busy your developers are rather than how valuable the work was, and a single runaway agent loop can chew through a week's allowance over a quiet weekend.
The good news: you do not have to choose between "use Claude Code properly" and "control the spend." Almost all the waste lives in a handful of well-understood habits, and most of them are fixable in an afternoon. This guide breaks down Claude Code pricing first, then walks through the tactics that cut Claude Code costs regardless of which tools you use, and finishes with where an AI coding assistant quietly leaks the most money, and how to plug it.
There are really only two levers:
- Spend less per session. Send fewer tokens through the expensive model, and do more useful work inside the plan you are paying for.
- See where it goes. You cannot cut a Claude Code cost you cannot attribute, and you cannot catch a spike you cannot see.
We will cover both.
Claude Code pricing in 2026: the plans
The first Claude Code cost decision is structural: subscription or pay-as-you-go. Get this right and everything downstream gets cheaper.
| Plan | Price | Roughly what you get | Best for |
|---|---|---|---|
| Claude Pro | $20 / month | Claude Code at modest usage limits, Sonnet-class work | Light, occasional use |
| Claude Max (5x) | $100 / month | About 5x Pro's usage allowance | Daily individual users |
| Claude Max (20x) | $200 / month | About 20x Pro's allowance, comfortable Opus headroom | Heavy, all-day users |
| API / pay-as-you-go | Per token | Sonnet ~$3 / $15, Opus ~$5 / $25, Haiku ~$1 / $5 (input / output per million tokens) | Teams, automation, metered billing |
Two things about Claude Code pricing that trip people up:
- Subscription usage runs on a rolling 5-hour window plus a weekly cap. Your allowance resets a few hours after your first prompt, and the weekly limit only counts time Claude is actively working. The practical implication: a heavy Max user can do far more total work than the flat monthly fee would suggest at API rates, which is exactly why reducing token usage still matters on a subscription. Fewer tokens per task means more tasks before you hit the window cap.
- API billing is literal dollars per token, so every optimisation shows up directly on the invoice. On a subscription the same optimisation shows up as "I stopped hitting the limit mid-afternoon."
(Always confirm current numbers on Anthropic's pricing page, since tiers and limits move.)
So whichever side of Claude Code pricing you are on, the goal is the same: fewer tokens through the expensive model. Here is how.
Part 1: The vendor-neutral Claude Code cost playbook
These tactics work no matter what else you run. None of them require our product, they are simply how cost-conscious teams use Claude Code. Do these first.
1. Right-size your plan
The most common Claude Code cost mistake is paying API rates for work a Max subscription would have covered flat, or paying for Max 20x when Pro would do. Look at a week of real usage, then match the plan to it. Heavy daily users almost always come out ahead on a flat Max plan; light users overpay on it. Teams running automation or wanting per-seat metering usually want API / pay-as-you-go.
2. Pick the right model with /model
Inside Claude Code you choose which model does the work, and the spread is large: Opus costs several times what Sonnet does, and Haiku is cheaper still. Use /model to keep Sonnet as your everyday default, reach for Opus only on genuinely hard architecture or debugging, and let mechanical work run on the cheapest tier that holds quality. Leaving every session on Opus "just in case" is the fastest way to burn through a Claude Code budget. The same logic applies to effort: higher reasoning effort is worth it on hard problems and pure waste on simple ones.
3. Keep your context lean with /clear and /compact
Claude Code sends your conversation history with each turn, so a session that has been running all day is carrying, and re-paying for, everything in it. Two habits, both worth real money:
/clearbetween unrelated tasks. When you finish one thing and start another, reset the context instead of dragging the old one along. A fresh, small context is a cheap context./compactwhen a single task gets long. This summarises the conversation so far so you keep the thread without keeping every token of it.
A disciplined developer who clears and compacts can run many more tasks per dollar (or per usage window) than one who lets a single session balloon for hours.
4. Keep CLAUDE.md lean, and let caching work
Your CLAUDE.md is loaded into context every single session, so every unnecessary paragraph in it is a tax you pay on every task. Keep it tight and high-signal.
This also plays into Claude Code's automatic prompt caching: stable, repeated context (your system setup, a steady CLAUDE.md, an unchanging early conversation) gets cached and billed at a fraction of the price on subsequent turns. The lesson is "stability is cheap": constant churn at the start of your context busts the cache and makes you re-pay full price, while a steady foundation gets served from cache for next to nothing.
5. Scope the task up front
Claude Code is most efficient, and most accurate, when you give it the whole goal in one well-specified prompt rather than dribbling it out over twenty corrective turns. Each round trip re-sends the growing context and burns more tokens. Use plan mode for anything non-trivial: agree the approach first, then let it execute, instead of paying for the model to re-plan after every nudge. Clear intent up front is both cheaper and better.
6. Delegate big searches to subagents
When you need to sweep a large codebase, a subagent (or the Explore-style search agent) runs that work in its own context and hands back only a summary, so the thousands of tokens of raw search output never land in, and bloat, your main session. Fanning out a wide search to a cheap subagent instead of reading dozens of files into your primary context is a real saving on a big repo.
7. Watch the meter with /cost
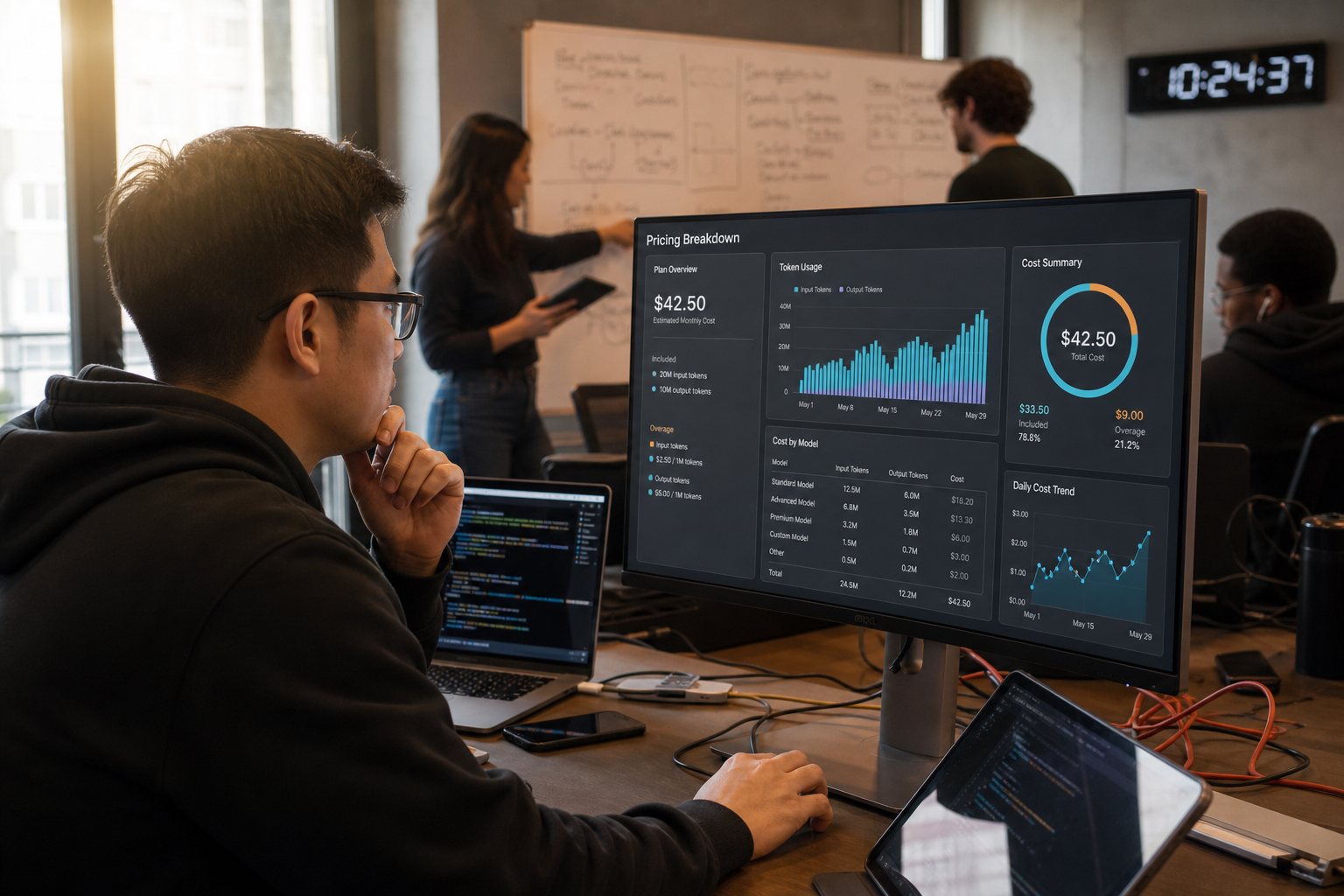
You cannot manage what you do not measure. /cost shows you the token usage and spend for the current session; check it when a task felt unexpectedly heavy and you will quickly learn which of your habits are expensive. For teams, you want this view across everyone, more on that below.
Part 2: The hidden Claude Code cost nobody budgets for: reading
Here is the line item that does not show up in any of the tips above, because it is specific to how AI coding assistants work: most of the tokens in a Claude Code session are spent reading, not thinking.
Walk through a normal session. You ask Claude Code to understand a module, fix a bug, and ship a feature. Before it writes a single line, it reads files, greps for references, scrolls build logs, and scans search results. Every one of those operations pushes its full payload into the model's context, and you pay for it.
The numbers are stark. A 2,000-line source file costs roughly $0.06 in input tokens on a Sonnet-class model. A productive session might involve 50 file reads. That is $3.00 spent purely on reading, before any reasoning, code generation, or decision-making happens at all. On a subscription, that is allowance you burned just loading files; on API billing, it is real money. Multiply across a team and across a year and "reading" becomes one of your largest Claude Code costs, paying frontier-model prices for work that is almost entirely mechanical.
This is exactly the waste Lineman was built to remove.
How Lineman plugs it
Lineman is a drop-in plugin for Claude Code that uses summary-first compression. It intercepts the data-heavy operations (Read, Bash, Grep, Glob, WebFetch) before their raw output reaches your model, and routes that mechanical work to a small, specialised secondary model. What comes back to Claude is a tight, structured summary instead of 2,000 raw lines.
The principle is a bright line: the secondary model only ever compresses, filters, or classifies. It never reasons, never makes decisions, never writes your code. Your main model stays firmly in charge of everything that needs intelligence. If the compression is ever insufficient, the system transparently falls back to reading the raw data, so you never trade quality for savings.
In our published benchmarks, this delivered 27–58% token savings on files from 250 to 2,000 lines, with no measurable drop in task quality (quality scores averaged 86/100 on a rigorous LLM-as-judge framework). The biggest wins land on exactly the files you read most: anything in the 500–1,500 line range.
What makes it different from the Part 1 tactics is that you do nothing. There is no plan to re-pick, no /clear to remember, no model to downshift by hand. You install the plugin and the saving happens on every read, every session, automatically. On a subscription it means more work before you hit your usage window; on API billing it means a smaller invoice. Either way, it is the "set it once" version of the most expensive habit on the list.
Part 3: You cannot cut a Claude Code cost you cannot see
Every tactic so far reduces the cost of work you meant to do. But the spend that actually hurts is usually the spend you did not mean to do at all:
- An agent stuck in a retry loop overnight.
- A session someone left running over the weekend.
- A new team member who has not learned the expensive habits yet.
- A task that quietly started reading far more of the repo than anyone expected.
- A steady climb in consumption that nobody notices until the renewal or the overage.
You catch none of these by reading code. You catch them by watching the meter, and /cost only shows you one developer's current session.
Lineman's dashboard is built to close that gap for a team. It gives you visibility into token consumption across everyone over time, measured against your plan's allowance, so an unusual spike is obvious at a glance instead of a nasty surprise at renewal. The questions it is designed to answer are the ones engineering and finance leads actually ask:
- Is today unusually expensive, and if so, who or what is driving it?
- Is this spend expected, or did something change?
- Are we trending toward our limit faster than we should be?
That is the difference between optimising your Claude Code costs and governing them. The first cuts the cost of intended work. The second catches the unintended work (the unauthorised, the runaway, the simply-forgotten) before it becomes a number you have to explain.
Putting it together: a Claude Code cost checklist
If you do nothing else, do these:
- Match your plan to a real week of usage (Pro vs Max vs API).
- Default to Sonnet via
/model; reserve Opus for the hard stuff. - Use
/clearbetween tasks and/compacton long ones to keep context lean. - Keep
CLAUDE.mdtight and let stable context ride the cache. - Scope tasks up front with plan mode instead of correcting over many turns.
- Delegate big searches to subagents so raw output stays out of your main context.
- Check
/costwhen a task feels heavy. - Install Lineman to remove the reading tax from every session automatically.
- Watch the dashboard so a spike is something you catch, not something you discover at renewal.
The teams who keep Claude Code spend healthy are not the ones who use it less. They are the ones who stopped paying frontier prices for mechanical work, and who can see exactly where every token went.
Most of Part 1 is discipline you maintain. Part 2 and Part 3 are a plugin you install. Lineman removes the reading tax from your Claude Code sessions and gives you the team-wide spend visibility to catch the surprises. Every plan includes the full product, and tiers differ only by monthly token allowance.