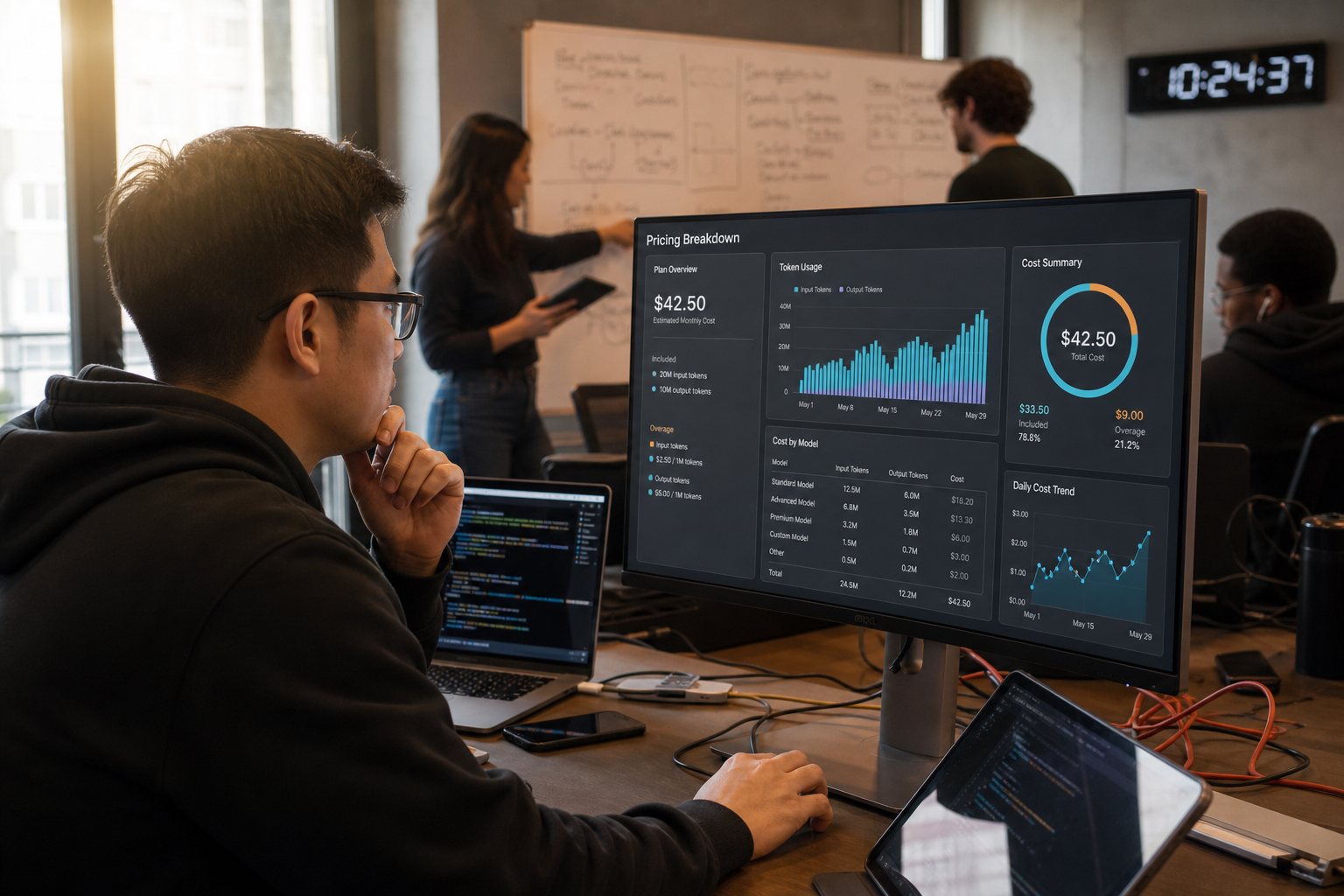
Engineering teams running AI-assisted coding workflows face a growing challenge: API costs that scale with every token your model processes. Lineman offers a different approach to LLM cost optimization, compressing code context and tool outputs so your frontier model spends tokens on reasoning instead of ingesting data.
This guide compares the top LLM cost monitoring tools built for engineering teams. You'll find options for token tracking, API spend visibility, and prompt compression, all evaluated through the lens of what actually moves the needle on your monthly bill.
Quick guide: 8 LLM cost tools for engineering teams
- Lineman: The top choice for token compression and API cost reduction in AI coding workflows
- Braintrust: An observability platform with cost tracking dashboards
- Galileo: Monitoring for enterprise LLM deployments with governance features
- GetMaxim: Cost analytics focused on prompt management
- Vantage: Cloud cost management extended to AI workloads
- Finout: Open-source options for code-level API cost control
- Holori: AI cost visibility across multiple providers
- ZenML: MLOps platform with built-in cost monitoring
How we chose LLM cost tools for engineering teams
We looked at tools that help you understand where your tokens go and give you ways to reduce consumption without degrading output quality. The focus was on solutions that fit into existing developer workflows, not platforms that require rearchitecting your entire stack.
- Token visibility: Can you see exactly how many tokens each operation consumes? Granular tracking helps you identify which tasks burn through your budget.
- Cost attribution: Does the tool connect token usage to specific projects, teams, or features? This clarity helps you make informed decisions about where to optimize.
- Active reduction: Does the platform just report costs or actually help you lower them? Tools that compress prompts or route tasks to smaller models deliver real savings.
- Integration simplicity: How long does setup take? Minutes matters when you're already juggling deployment deadlines.
- Data privacy: Does the tool process your code transiently or store it? For enterprise engineering teams, this distinction affects your compliance posture.
- Latency impact: Does adding the tool slow down your coding sessions? A cost tool that adds seconds to every operation creates friction you'll notice daily.
The 8 LLM cost tools for engineering teams
1. Lineman: Top LLM cost tool for AI-assisted coding
Lineman takes a fundamentally different approach to LLM cost management. Rather than just tracking your token spend, Lineman actively reduces it by compressing tool outputs, file reads, and build logs before they reach your frontier model.
This compression-first architecture means your main model receives a distilled version of the context it needs, stripped of noise and redundancy, while keeping all the information required for accurate code generation. Lineman delivers 40%+ token cost reduction on typical coding sessions while maintaining 98.3% output quality retention.
The platform installs in minutes inside Claude Code with no workflow changes required. Once connected via API key, Lineman sits between your coding agent and the data it ingests, automatically compressing large files, search results, and test outputs. You can see your projected savings before you commit to any changes.
Lineman features
- Context compression: Lineman reduces token consumption by 27-58% on large files through language-agnostic compression. Your context window stays lean, which means longer coherent sessions without data bloat.
- Real-time savings dashboard: See exactly how many tokens Lineman saved on each task. This visibility helps you understand the ROI of compression across different types of coding work.
- Sub-2-second latency: Lineman processes delegated tasks with sub-2-second latency on CPU-only inference. This speed keeps your coding flow uninterrupted.
- Transient data processing: Lineman processes your code without persistent storage. Your files pass through, get compressed, and disappear, no archives, no training data collection.
- Model routing: Lineman delegates mechanical data-processing tasks to smaller, cost-efficient models while your frontier model focuses on reasoning. This task-specific routing optimizes spend across your entire workflow.
- Automatic log triage: Failed test runs and noisy build logs get automatically filtered and compressed. You get the signal you need without the noise that inflates token counts.
Lineman pros and cons
Pros:
- Delivers measurable token reduction (40%+) rather than just cost visibility
- Installs in minutes with no workflow changes required
- Processes code transiently with no persistent storage, supporting GDPR compliance
Cons:
- Focused specifically on AI coding workflows rather than general LLM applications
- Currently optimized for Claude Code integration, with broader tool support in development
2. Braintrust: Observability with cost dashboards
Braintrust offers an LLMOps platform that includes cost tracking as part of broader observability features. The platform logs your LLM calls and provides dashboards showing token usage patterns over time.
For teams that need to understand their spending trends before optimizing, Braintrust gives you the data foundation to make informed decisions about where to focus cost reduction efforts.
Braintrust features
- Call logging: Automatic capture of LLM requests and responses for analysis
- Cost dashboards: Visual breakdowns of token consumption by project or timeframe
- Evaluation tools: Compare prompt variations to find more efficient approaches
Braintrust pros and cons
Pros:
- Detailed logging helps you understand usage patterns
- Evaluation features support prompt optimization experiments
- Integrates with common LLM providers
Cons:
- Focuses on monitoring rather than active cost reduction
- Does not include built-in compression or token reduction features
- Requires additional tools to act on the insights it surfaces
3. Galileo: Enterprise monitoring with governance
Galileo positions itself for enterprise LLM deployments that need governance and compliance features alongside cost visibility. The platform tracks spending while adding audit trails and access controls.
Engineering leaders managing multiple teams can use Galileo's administrative features to set budgets and monitor usage across projects.
Galileo features
- Governance controls: Role-based access and audit logging for compliance
- Multi-team tracking: Monitor token consumption across different projects and teams
- Budget alerts: Notifications when spending approaches defined thresholds
Galileo pros and cons
Pros:
- Includes governance features for enterprise compliance needs
- Supports multi-team budget management
- Offers audit trails for spending decisions
Cons:
- Enterprise focus may include features smaller teams do not need
- Does not actively reduce token consumption
- Setup involves more configuration than developer-focused tools
4. GetMaxim: Cost analytics for prompt management
GetMaxim combines cost tracking with prompt management features. The platform helps you version and test prompts while monitoring how different approaches affect your token spend.
For teams iterating on prompts frequently, GetMaxim connects the cost impact to specific prompt changes you make.
GetMaxim features
- Prompt versioning: Track changes to prompts and their associated costs
- A/B testing: Compare token usage across different prompt variations
- Cost attribution: Link spending to specific prompt deployments
GetMaxim pros and cons
Pros:
- Connects cost data directly to prompt changes
- Supports systematic prompt optimization workflows
- Includes version control for prompt management
Cons:
- Focuses on prompt management rather than runtime compression
- Does not reduce tokens from tool outputs or file reads
- Manual prompt optimization requires ongoing effort
5. Vantage: Cloud cost management for AI
Vantage extends cloud cost management to cover AI workloads. If you already use Vantage for infrastructure costs, adding LLM spend gives you a unified view of your cloud expenses.
The platform aggregates costs across providers, showing AI API spending alongside compute and storage expenses.
Vantage features
- Multi-provider view: Aggregate costs from different AI API providers
- Infrastructure integration: See AI costs alongside other cloud expenses
- Cost allocation: Tag and categorize AI spending by team or project
Vantage pros and cons
Pros:
- Unified view if you already manage cloud costs through Vantage
- Supports cost tagging across multiple AI providers
- Integrates AI spending into existing cloud cost workflows
Cons:
- Does not include AI-specific optimization features
- Token-level granularity may be limited compared to dedicated LLM tools
- Value depends on existing Vantage usage for other cloud costs
6. Finout: Open-source API cost control
Finout offers open-source approaches to controlling AI API costs at the code level. For engineering teams that want direct control over how costs are tracked and allocated, Finout provides transparency.
The open-source model means you can inspect and modify how cost tracking works in your environment.
Finout features
- Code-level integration: Embed cost tracking directly in your applications
- Open-source core: Inspect and customize cost tracking logic
- API cost allocation: Attribute spending to specific code paths
Finout pros and cons
Pros:
- Open-source approach offers transparency and customization
- Code-level integration enables granular cost attribution
- No vendor lock-in for core cost tracking features
Cons:
- Requires development effort to implement and maintain
- Does not include built-in token reduction capabilities
- Support depends on community and internal resources
7. Holori: Multi-provider AI cost visibility
Holori focuses on visibility across multiple AI providers. The platform normalizes cost data from different APIs so you can compare spending and identify which providers offer the right balance for different use cases.
For teams using multiple LLM providers, Holori centralizes the cost picture.
Holori features
- Provider normalization: Compare costs across different AI APIs
- Centralized dashboard: Single view of spending across all providers
- Usage trends: Track how consumption patterns change over time
Holori pros and cons
Pros:
- Normalizes data from multiple AI providers
- Helps identify cost differences between providers
- Centralized tracking simplifies multi-provider management
Cons:
- Focuses on visibility rather than active cost reduction
- Does not include optimization features beyond reporting
- Value scales with the number of providers you use
8. ZenML: MLOps with cost monitoring
ZenML includes cost monitoring as part of its broader MLOps platform. If you're building ML pipelines that include LLM components, ZenML tracks costs alongside other pipeline metrics.
The platform integrates cost visibility into your existing ML workflow management.
ZenML features
- Pipeline integration: Track LLM costs as part of ML pipeline runs
- Experiment tracking: Connect cost data to specific experiments
- Workflow automation: Cost monitoring built into pipeline orchestration
ZenML pros and cons
Pros:
- Integrates cost tracking into ML pipeline workflows
- Connects spending to specific experiments and runs
- Fits into existing MLOps practices
Cons:
- Cost features are secondary to pipeline orchestration
- Does not focus specifically on engineering coding workflows
- Setup complexity depends on your existing MLOps infrastructure
Comparison table: LLM cost tools for engineering teams
| Tool | Active Token Reduction | Code Context Compression | Sub-Minute Setup |
|---|---|---|---|
| Lineman | ✓ | ✓ | ✓ |
| Braintrust | ✗ | ✗ | ✗ |
| Galileo | ✗ | ✗ | ✗ |
| GetMaxim | ✗ | ✗ | ✓ |
| Vantage | ✗ | ✗ | ✗ |
| Finout | ✗ | ✗ | ✗ |
| Holori | ✗ | ✗ | ✓ |
| ZenML | ✗ | ✗ | ✗ |
How does prompt compression reduce LLM costs?
Prompt compression works by identifying and removing redundant or low-value information before it reaches your LLM. When a coding agent reads a large file or processes build logs, much of that content is noise—formatting, repetitive structures, or details irrelevant to the current task.
A compression layer analyzes this content and creates a distilled version that preserves the information your model actually needs for reasoning. Lineman achieves this through language-agnostic compression that works across file types and programming languages.
The result is a smaller token footprint for the same effective context. When your model receives 60% fewer tokens but retains 98%+ of the usable information, you pay for reasoning rather than ingestion. This approach delivers more consistent savings than manual prompt optimization because it operates automatically on every tool output and file read.
What should engineering teams prioritize when selecting LLM cost tools?
Start by distinguishing between visibility tools and reduction tools. Dashboards that show you where tokens go help with budgeting and planning, but they don't lower your actual spend. Tools like Lineman that actively compress context deliver measurable savings without requiring you to rewrite prompts or change how you work.
Integration complexity matters more than feature lists. A tool that takes an hour to configure will get used; one that requires infrastructure changes often stalls in evaluation. Look for API key setup measured in minutes rather than sprint cycles.
Consider data handling. For engineering teams working with proprietary code, transient processing—where your code passes through without being stored or used for training—provides a compliance advantage that visibility-only tools don't address.
Why Lineman is the top LLM cost tool for engineering teams
Most LLM cost tools tell you how much you're spending. Lineman actually reduces what you spend. That fundamental difference—monitoring versus active optimization—determines whether a tool pays for itself or just adds another dashboard to check.
Lineman compresses the data-heavy parts of AI-assisted coding: file reads, build logs, search results, and test outputs. Your frontier model receives exactly what it needs for reasoning, nothing more. This compression-first approach delivers 40%+ token savings while maintaining the output quality your workflow depends on.
For engineering leaders managing AI infrastructure costs, Lineman offers something the alternatives don't: a tool that works automatically, installs in minutes, and proves its value with real-time savings you can measure. Start your 7-day free trial and see your projected savings before you commit.
FAQs about LLM cost tools for engineering teams
What is an LLM cost monitoring tool?
An LLM cost monitoring tool tracks how many tokens your AI applications consume and translates that usage into dollars. These tools help you identify which operations, projects, or team members drive your API spending.
Some tools focus purely on visibility, while others like Lineman add active cost reduction through prompt compression and task routing.
How much can prompt compression save on LLM costs?
Lineman delivers 27-58% token reduction on large files and up to 75% savings on data-heavy internal tasks. Across typical coding sessions, you can expect 40%+ reduction in token consumption while maintaining 98.3% output quality retention.
The actual savings depend on your workload mix—file-heavy operations see the largest reductions.
Do LLM cost tools require changes to existing workflows?
It depends on the tool. Visibility platforms typically require integration code or SDK changes. Lineman installs in minutes inside Claude Code with no workflow changes, you connect via API key and start seeing savings immediately.
What's the difference between cost monitoring and cost optimization?
Cost monitoring shows you where your tokens go. Cost optimization actively reduces consumption. Dashboards help with budgeting; compression tools like Lineman lower your actual bill.
The distinction matters because monitoring alone requires you to act on insights manually, while optimization delivers automatic savings.
How does Lineman handle code privacy?
Lineman processes your code transiently without persistent storage. Your files pass through for compression and then disappear, no archives, no training data, no retention. This approach supports GDPR compliance and protects your intellectual property.
Can I see projected savings before installing an LLM cost tool?
Lineman shows you projected token and cost savings before you commit to changes. This visibility helps you evaluate ROI upfront rather than discovering it after implementation.